
The creative "Diffraction Pattern"
The surprisingly logical problem at the root of many generative creativity issues. Why those problems will be hard to address. Why you might want to invest in property in Burnley, Lancashire.


“AI can’t be creative.” I’m sure you’ve seen this take a lot recently.
Generative models do indeed have some (nuanced) issues with creativity. But for this specific issue that question is actually beside the point.
And this is important, because it means we can’t actually fix all of these problems by improving the raw creative potential of these systems.
This is because any amount of technical creativity can become worthless if it is still predictable.
And because prediction and pattern replication are where these models live.
Remember: An LLM is trying to predict a “correct” next token. An image model is trying to shape a visual landscape until it matches specific features of the images it has been trained on.
The Priya problem
I’ve been playing around with Claude, testing its performance on creative writing tasks. And especially its ability to iterate on specific themes. And I soon started noticing patterns and one of the first things I noticed was “Priya”, a name that was recurring time and time again throughout the works as a secondary character.
And as I created more and more example texts, I started to notice more and more patterns.
So I asked Claude to work back through the examples and just look for patterns. Claude did indeed locate Priya in nearly a third of the stories. It also cheerfully reported a whole host of similar patterns across every aspect of the material. Half of the (rural fantasy themed) stories were set in Burnley, Lancashire. Half the stories were set on a Tuesday. A lot of patterns…
The existence of these patterns is probably not going to come as a surprise to any of my audience.
It’s easy to ascribe them to creative failure. But that’s not actually the issue (or at least not the only one).
The real issue here is that those choices likely represent the model’s optimal choices in that context, and so it then becomes inevitable that patterns will surface when usage of the model is scaled, no matter how technically creative the system is actually being.
If you are an aspiring author, Priya seems like a good choice of name for a character. It’s a very common name globally, but previously quite underexposed in western writing (at least in the UK). It’s diverse, but with broad roots, memorable, not associated with any problematic stereotypes or prior usage, or laden with any obvious etymological landmines that the author might be badly prepared to unpack.
Creativity wise, it would seem to represent a solid choice.
It’s very difficult to identify in the specific, why this pattern has emerged here.
But at this point the why ship has actually sailed, and the specific reason doesn’t matter much; training data distribution, global web effects, something deeper in the base model’s reasoning.
What matters is that the model considers Priya optimal, and that we are then all asking the same model for optimal, often in service of very similar objectives.
So we end up with a creative diffraction pattern. A concept that should be superficially familiar to those of us who stuck around for too long in the vicinity of a physics teacher. If you don’t know what that is, you can be reassured that this is one of those things that is complicated enough that I’m not even going to try to explain it here, but also complicated enough that there is actually very little risk that anyone will spot any technical mistakes you might make in deploying the analogy.
The comparative aspect is actually straightforward. These are the patterns formed by light interacting with specific types of obstacles or apertures.
Let’s not get smug about this
It would be remiss of me to not point out that real people are famously bad at this stuff too.
Case in point - Claude also helpfully pointed out that, aside from the Priya problem, a similar 1/3rd of the protagonists had the same name as well. And I was the one specifying those. Whoops.
Some of those patterns do indeed spread very broadly throughout the species.
“Think of a number between one and ten”: research here tells us that there is about a 33% chance that you picked a seven, and basic observation of human nature tells us that there is about a 66% chance that you already knew that “everyone picks a seven” and then guiltily substituted another number at the last minute.
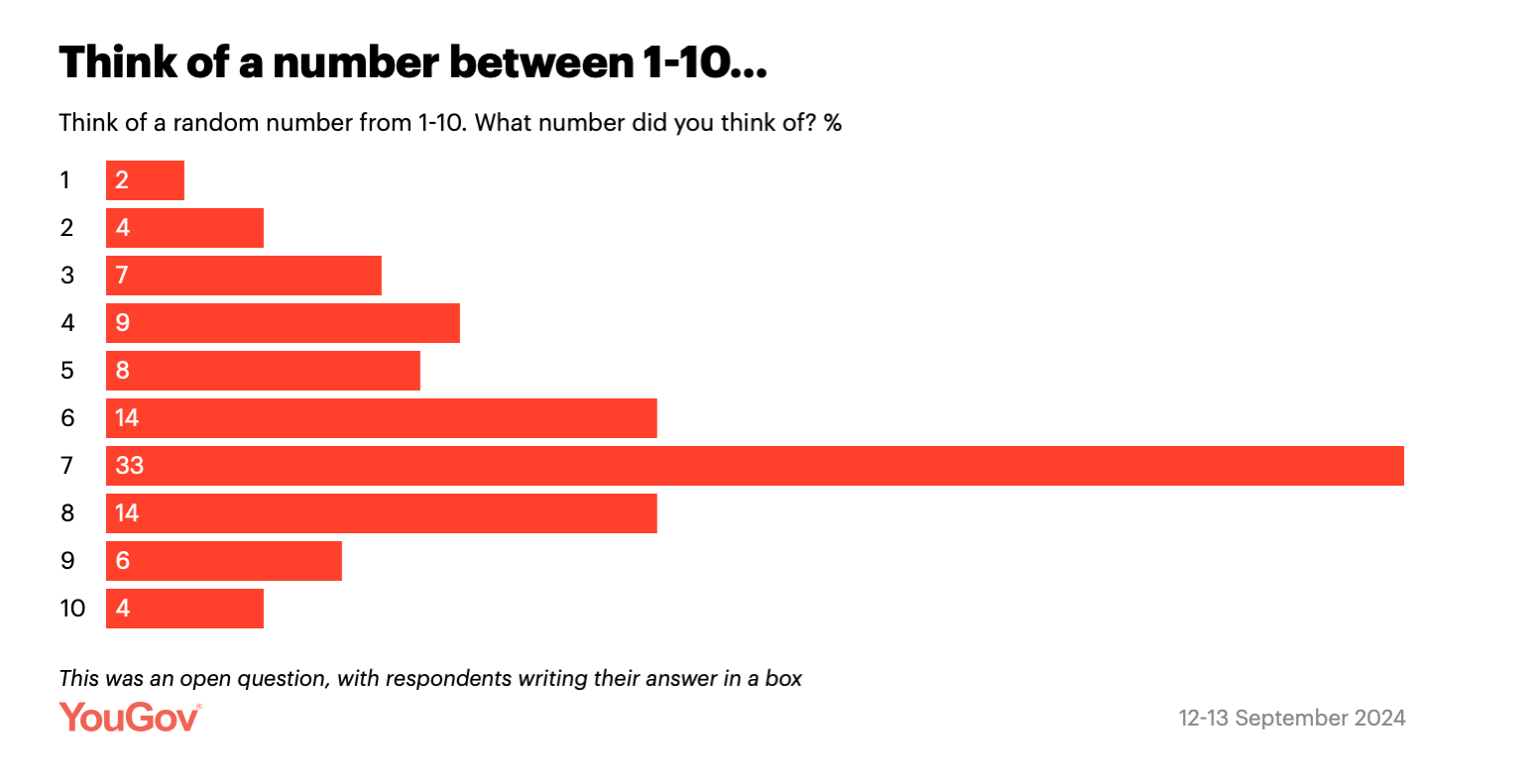
But in the broader sense of things, the diversity of human experience and human view points and human contexts has historically smoothed over a lot of these spikes, and generally concealed the extent of some of our personal failings with regard to RNG.
But there are far fewer LLM models than there are people. And so this becomes a very real, and quite technically intractable problem.
Why this is such a potent problem
First of all, this is hard to spot. Poor creative performance isn’t actually driving this, so unless you are creating a lot of examples of work, you won’t have a chance to spot these choices until they have already become patterns. Worse those patterns extend through every aspect of any media that is being created using AI. There is a paper here describing a filter approach to this, which reports that they have identified, and are filtering for 8K+ distinct patterns. No matter how attentive a human co-creator is, they are absolutely not going to find and fix that many patterns in post.
And, importantly, this problem comes from the way the systems are intended to work and is compounded by the relatively low number of models now doing a massive amount of work. You can’t fix this problem by training the system with more, or better, data, if the distribution of that data still inevitably collapses to a single point at output. We can expect these patterns to be more intractable than many other current creative limitations within these systems because there isn’t actually an obvious malfunction here to be fixed. Our problem is literally the model’s KPI. Other research tells us that the alignment work performed on these models to broadly improve performance, actually amplifies this specific problem.
This is certainly a know problem to LLM researchers, known as “Mode collapse”. But I don’t think the implications of it are well understood by most creatives trying to use these systems to do work.
And a lot of the obvious technical tools to manage this such as filters or temperature settings are really just moving the lumps around, rather than directly addressing the problem. We can expect this to work on a small scale, but as soon as we scale the fix, we can expect that fix to evaporate into just another set of patterns.
Conclusion (and follow up articles)
So, if you have any interest at all in using AI to create content for any purpose, commercial or otherwise you need to understand this issue, and why we can expect it to persist (and even amplify) over time.
If you are interested in a follow up here, I’m intending to write a couple more on the same topic. One of which will take a much deeper dive into the technical basics of this issue (and some potential routes to addressing it), and another which will take a closer look at the commercial aspects of the problem, and especially with regard to how we can expect this issue to badly impact algorithmic performance for AI generated content.
As stated, scaled mitigation will be difficult. But until these markets (or at least awareness of this problem) scale, some of those band aid solutions may help individual practitioners.
Beyond that, the best immediate defence here is as much co-creation from a human as possible. The more direction exists in the process, the less room there is for these patterns to emerge. We may have our limitations, but we do excel at creating entropy.